
SIS – Sistemas Instrumentados de Seguridad - Parte 2

Una visión práctica – Parte 2
Hemos vista en el artículo anterior, algunos detalles del Ciclo de Vida de Seguridad y Análisis de Riesgo. Veremos ahora, la segunda parte, algo sobre Ingeniería de Confiabilidad.
Confiabilidad de Sistemas de Mediciones
La confiabilidad de sistemas de mediciones puede cuantificarse como el tiempo medio entre fallos ocurridos en el sistema. En este contexto, fallo significa la ocurrencia de una condición inesperada que causa un valor incorrecto en la salida.
Principios de Confiabilidad
Se puede cuantificar la confiabilidad de sistemas de mediciones como la habilidad del sistema ejecutar su función dentro de límites y condiciones de funcionamiento dentro de un tiempo definido. Infelizmente, varios factores, tales como las tolerancias de los fabricantes según las condiciones de operación, dificultan a veces esta determinación, y en la práctica lo que se logra es exprimir estadísticamente la confiabilidad a través de la probabilidad de los fallos que ocurrieron en un cierto período.
En la práctica la grande dificultad es determinar lo que es un fallo. Cuando la salida de un sistema está incorrecta es algo difícil de se interpretar cuando comparado con la pérdida total de la salida de medición.
Cuantificación de Confiabilidad en términos casi-absolutos
Como demostramos, la confiabilidad es esencialmente de naturaleza probabilística y se puede cuantificar en términos casi-absolutos a través del tiempo medio entre fallos (MTBF) y el tiempo para fallar (MTTF). Hay que subrayar que estos dos tiempos son normalmente los valores medios calculados a través de dispositivos idénticos y, por lo tanto, para cualquier instrumento en particular los valores pueden ser distintos de la media.
El MTBF es un parámetro que exprime el tiempo medio entre fallos ocurridos en un instrumento, calculado en un determinado período. En casos en los cuales los equipos poseen alta confiabilidad, será difícil contarse el número de ocurrencias y podrán generar números imprecisos al MTBF y entonces se recomienda usar el valor del fabricante.
El MTTF es una manera alternativa de se cuantificar la confiabilidad. Es normalmente utilizado en dispositivos termopares, pues son descartados al fallar. El MTTF exprime el tiempo medio antes que ocurra el fallo, calculado en número idénticos de dispositivos.
La confiabilidad final asociada según la importancia al sistema de medición se exprime por el tiempo medio de reparo (MTTR), o sea, el tiempo medio para reparar un instrumento o aun el tiempo medio de sustitución de un equipo.
La combinación del MTBF y el MTTR muestra la disponibilidad:
Disponibilidad = MTBF/ (MTBF+MTTR)
La disponibilidad mide la proporción de tiempo en el cual el dispositivo trabaja sin fallos.
El objetivo en sistema de mediciones es maximizar el MTBF y minimizar el MTTR y, consecuentemente, maximizar la disponibilidad.
Modelos de Fallos
El modelo de un fallo de un dispositivo puede cambiar durante su ciclo de vida, permaneciendo inalterado, disminuyendo o aumentado.
En componentes electrónicos, es común haber el comportamiento visto en la figura 1, también conocido como “bathtub curve” (curva de la bañera)
.jpg)
Figura 1 – Curva típica de la variación de confiabilidad de un componente electrónico
Los fabricantes generalmente aplican pruebas de burn-in de manera a eliminarse la etapa T1 hasta que los productos sean distribuidos en el mercado.
Por otro lado, los componentes mecánicos presentarán una tasa de fallo más grande en el final de su ciclo de vida, de acuerdo con la figura 2.
.jpg)
Figura 2 – Curva típica de la variación de confiabilidad de un componente mecánico
En la práctica, los sistemas son composiciones electrónicas y mecánicas y los modelos de fallos son complejos. Cuanto mas componentes, mayor la incidencia y probabilidad de fallos.
Leyes de la confiabilidad
Existen diversos componentes en la confiabilidad y el sistema de medición es complejo. Podemos tener componentes en serie y en paralelo.
La confiabilidad de componentes en serie debe tener en cuente la probabilidad de fallos individuales en determinado período. Para un sistema de medición con n componentes en serie, la confiabilidad Rs es el producto de la confiabilidades individuales: Rs = R1xR2...Rn.
Suponga que haya un sistema de medición formado por un sensor, un elemento de conversión y un circuito de procesamiento de señal, cuyas confiabilidades sean 0.9, 0.95 e 0.099. En este caso la confiabilidad del sistema será 0.9x0.95x0.009 = 0.85.
La confiabilidad puede ser aumentada a través de componentes paralelos, lo que significa que el sistema falla se todos los componentes fallaren. En este caso la confiabilidad RS es dada por:
Rs = 1 – Fs, donde Fs es la no-confiabilidad del sistema.
La no-confiabilidad es Fs = F1xF2...F3.
Por ejemplo, en un sistema de medición segura existen tres instrumentos idénticos paralelos. La confiabilidad de cada uno es 0.95 y la del sistema es dada por:
Rs = 1 –[ (1-0.95)x(1-0.95)x(1-0.95)] = 0.999875
Como mejorar la confiabilidad de un sistema de medición
El intento práctico es minimizar el nivel de los fallos. Un requisito importante es garantizar que se conozca y actúe antes del tiempo T2 (figuras 1 y 2) cuando la frecuencia estadística de los fallos aumenta. El ideal es hacer que T (período o ciclo de vida) sea igual a T2 y los tiempos aumenten sin fallos
Existen varias maneras de aumentar la confiabilidad de un sistema de medición:
- Elección de los instrumentos: se debe siempre estar atento a los instrumentos especificados, sus influencias relativas al proceso, los materiales, el ambiente, etc.
- Protección de los instrumentos: protegiendo los instrumentos adecuadamente se puede ayudar a garantizar nivel mayor de seguridad. Por ejemplo, los termopares deberían estar protegidos en condiciones adversas de funcionamiento.
- Calibración regular: la mayoría de los fallos puede ser causadas por drifts que alteran y generan salidas incorrectas. Entonces, según la buena práctica de la instrumentación se recomienda que periódicamente los instrumentos sean inspeccionados y calibrados.
Redundancia: en este caso se tiene mas de un equipo trabajando en paralelo y accionado, a veces, automáticamente. La confiabilidad es mejorada significativamente.
Sistemas de Seguridad y Confiabilidad
Los Sistemas de Seguridad monitorean la condición de valores y parámetros de una planta dentro de los límites operacionales, e bajo condiciones de riesgo deben generar alarmes y poner las instalaciones en condición segura o mismo de shutdown.
Observe que las condiciones de seguridad se deben seguir e adoptar en fábricas en que las mejores prácticas de funcionamiento e instalación son una obligación tanto de empleados como de directores. Vale recordar que el primer concepto referente relativamente a la legislación de seguridad es asegurar que todos los sistemas sean instalados y operados de manera segura, y el segundo es que instrumentos y alarmes relativos a seguridad sean manejados con confiabilidad y eficiencia.
Los Sistemas Instrumentados de Seguridad (SIS) son responsables por la seguridad operacional y garantizan las paradas de emergencia dentro de los límites considerados seguros, siempre la operación ultrapasa estos límites. El objetivo principal es evitar accidentes dentro y fuera de las fábricas, tales como incendios, explosiones, daños a los equipos, protección de la producción y la propiedad y, mas aun, evitar riesgos de vidas o daños a la salude de la personas e impactos catastróficos a la comunidad. Se debe tener en mente que ningún sistema es totalmente inmune a fallos y siempre deben proporcionar una condición segura, mismo en caso de fallo.
Métricas utilizadas en el campo de Ingeniería de Confiabilidad relativa al SIS
1. Confiabilidad R(t)
La confiabilidad es una métrica desarrollada para determinar la probabilidad de éxito de una operación en determinado período de tiempo.
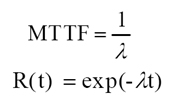
Cuando I (tasa de fallos) es muy pequeña, la función de no-confiabilidad (F(t)) o la Probabilidad de Fallo (PF) es dada por: PF (t) = It
.jpg)
Figura 3 – Confiabilidad R(t)
2. MTTR – Tiempo Medio de Reparo
La medición de confiabilidad exige que un sistema sea exitoso funcionando durante determinado tiempo. En este sentido, aparece la métrica del MTTR, que es el tiempo en lo cual se identifica un fallo y se lo repara (o restablece la normalidad operacional).
La tasa de restablecimiento del éxito operacional es dada por:µ = 1/MTTR.
En la práctica no es tan simple estimar esta tasa, principalmente cuando bajo actividades de inspección periódicas, pues el fallo puede ocurrir luego después de una inspección.
3. MTBF – Tiempo Medio entre fallos
El MTBF es una medida básica de confiabilidad en artículos reparables de un equipo y se puede exprimir en horas o años. Se usa normalmente en análisis de confiabilidad y sustentabilidad en sistemas y se puede calcular por la siguiente fórmula:
MTBF = MTTR + MTTF
Donde:
- MTTR = Tiempo Medio de Reparo
- MTTF = Tiempo Medio para Fallar = al inverso da suma de todas as tasas de fallos
Como o MTTR é muy pequeño en la práctica, es común asumir MTBF = MTTF
4. Disponibilidad A(t) e Indisponibilidad U(t)
Otra métrica muy útil es la disponibilidad. E define como la probabilidad de que un dispositivo esté disponible (sin fallos) cuando, en un tiempo t, se exige que el funcione dentro de condiciones normales para que fue proyectado.
Indisponibilidad es dada por: U(t) = - A(t)
Disponibilidad es función no solo de confiabilidad, pero es también función de mantenimiento. La Tabla 1 abajo muestra la relación entre confiabilidad, mantenimiento y disponibilidad. Observe en esta tabla que un aumento de capacidad de mantenimiento implica una disminución del tiempo necesario para realizar acciones de mantenimiento.
| Confiabilidad | Mantenimiento | Disponibilidad |
| Constante | Disminuye | Disminuye |
| Constante | Aumenta | Aumenta |
| Aumenta | Constante | Aumenta |
| Disminuye | Constante | Disminuye |
Tabla 1 – Relación entre Confiabilidad, Mantenimiento y Disponibilidad
.jpg)
Figura 4 – Confiabilidad, Disponibilidad y Costos
5. Probabilidad de Fallo en Demanda (PFDavg) y Prueba e Inspección Periódicos
PFDavg es la probabilidad de fallo de un sistema de prevención de fallos cuando ocurre un fallo. El nivel de SIL está relacionado con esta probabilidad y con el factor de reducción de riesgo (lo cuanto es necesario proteger para garantizar un riesgo aceptable si ocurrir un fallo).
PFD es el indicador de confiabilidad adecuado para sistemas de seguridad.
Sin ser sometido a prueba, la probabilidad de fallo tiende a ser 1.0 con el tiempo. Pruebas periódicas mantienen la probabilidad de fallo bajo límites deseables.
.jpg)
Figura 5 – Votación, PFD y Arquitectura
La figura 5 muestra detalles de arquitectura versus votación y PFD, y la figura 6 muestra la relación en PFD y el Factor de Reducción de Riesgo. Mas adelante, daremos mas detalles en artículos que complementan esta serie.

Figura 6 – Relación entre PFDavg y el Factor de Reducción de Riesgo
La Probabilidadde Fallo puede calcularse a través de la siguiente ecuación:
PFAvg = (Cpt x l x TI/2) + ((1-Cpt) x l x L xT/2), donde:
- l: tasa de fallo
- Cpt: porcentaje de fallos detectado por una prueba (proof test)
- TI: período de prueba
- LT: tiempo de vida de una unidad de proceso
PFDavg = (0.7) x 0.002 x ½ + (1-0.7) x 0.002 x 25/2 = 0.0082
Veamos un ejemplo: supongamos que una válvula es usada en un sistema instrumentado de seguridad y tenga una tasa de fallo anual de 0.002. A cada año se hace una prueba de verificación e inspección. Se estima que 70% de los fallos se detectan en estas pruebas. Esta válvula será utilizada durante 25 años y su demanda de uso es estimada a cada 100 años. ¿Cual la probabilidad media de fallo?
Usando la ecuación anterior tenemos:
- l: 0.002
- Cpt: 0.7
- TI: 1 año
- LT: 25 años
Conclusión
En términos prácticos lo que se busca es la reducción de fallos y consecuentemente de paradas y riesgos operacionales. Se busca el aumento de disponibilidad y también, en términos de procesos, la minimización de variabilidad con consecuencia directa en el aumento de rentabilidad.
En los próximos artículos veremos mas detalles sobre SIS. En la tercera parte veremos un poco sobre modelos de sistemas en serie y paralelos, árboles de fallos (Fault Trees), modelo Markov y algunos cálculos.
Referencias
- IEC 61508 – Functional safety of electrical/electronic/programmable electronic safety-related systems.
- IEC 61511-1, clause 11, " Functional safety - Safety instrumented systems for the process industry sector - Part 1: Framework, definitions, system, hardware and software requirements", 2003-01
- ESTEVES, Marcello; RODRIGUEZ, João Aurélio V.; MACIEL, Marcos. Sistema de intertravamento de segurança, 2003.
- Sistemas Instrumentados de Segurança - César Cassiolato
- “Confiabilidade nos Sistemas de Medições e Sistemas Instrumentados de Segurança” - César Cassiolato
- Sistemas Instrumentados de Segurança – Uma visão prática – Parte 1, César Cassiolato
Soluciones confiables

